Japanese Kanji is a Lossy Compression of Chinese Characters
9 min read
My fascination of languages started when I was learning my fourth language, Japanese. Despite having taken a semester of Mandarin in the past, I never took the time and wonder about their writing system. Japanese, however, was a language I had to master in just under a year before transferring to Japanese college of technology (kosen). During my time in the Japanese language school, I would always doubt myself. How can I master the Japanese writing system, with over ten thousand characters?
The Kanji Should Have not Existed#
It’s a controversial take, considering there are over 1 billion people whose native language uses kanji (hanzi) or its derivatives. As a non-native speaker, however, I always find myself fascinated of how seemingly inefficient the system is. It has tens of thousands of characters, which makes memorization a bottleneck of learning the language.
The truth is, the kanji used in day-to-day life does not consist of >10,000 characters. However, in historical, law, or medical writing, the number could be closer to 10,000. In order to formalize which of the 10,000 characters one needs to study in order to learn the language, the government made a list called jōyō kanji (常用漢字). The jōyō kanji count is only 2,136 characters, but it’s still 2,110 more characters than English.
The English alphabet comprises of 26 characters and all children of the age of 6 (or under) know every character. Do Japanese children know every jōyō kanji by 6? Nuh uh. The average Japanese student is expected to learn all 2,136 characters of jōyō kanji by 9th grade, around the age of 15. This means that a lot of work has to be poured into literacy education in Japan. For me, it meant that this “literacy education” was to be cramped into a year of Japanese language school.

Kanji is the Exception#
A logogram is a written character that represents a semantic component of a language, such as a word or morpheme.
Japanese Kanji and Chinese Hanzi are practically the only surviving logographic writing system in the modern world. Other languages, such as the Naxi Dongba script used in Yunnan, China, are only used in a narrow settings like religious practices. At its core, a logographic writing system presents one character for one meaning. In practice, however, it might have more than one meanings. An example of a widely used logographic symbols other than kanji is the symbols used in mathematics such as for integration, and for addition. One symbol, one meaning.
Japanese Kango (漢語) is a Lossy Compression#
Onyomi (音読み)#
In Japanese, kango (漢語) refers to words originated from China, that are read with onyomi reading. In Japanese, a kanji (漢字) can be read in two manners, onyomi and kunyomi (訓読み). Onyomi refers to the reading derived by sounds from Chinese, while kunyomi’s reading is derived from existing Japanese words, typically signified by the presence of hiragana. The table below highlights examples of semantically similar words in different readings.
| Meaning | Onyomi | Kunyomi |
|---|---|---|
| light pollution | kougai (光害) | hikari no gai (光の害) |
| road | douro (道路) | michi (道) |
| food | shokumotsu(食物) | tabemono (食べ物) |
Despite being semantically similar, onyomi words are more typically used in formal settings, such as in work presentations, lectures, or written documents. In contrast, kunyomi words are used in casual settings, appearing more friendly. As stated earlier, sometimes the kunyomi counterpart is preferred for spoken settings to minimize ambiguity.
Chinese-derived words (kango) account for 43-54% of the Japanese vocabulary1. In writing, kango makes up 60%, but only 18% in speech2. This highlights the prominence of kango in formal settings such as writing.
Assumptions#
When evaluating how sounds are converted from Chinese to onyomi, we shall see how many sound each language has. For example, English might seem like it has 26 sounds, but that is not correct. English has 26 characters, but each character can sound differently depending on the words.
Each letter “a” in the word “Australia” has a different sound. - The first A: /ɒ/ (as in “off” in some accents). The second a: /eɪ/ (as in “cake”). The third a: /ə/ (the “schwa” or neutral vowel). English allows 15,000+ possible syllables3. It is a language that loosely accepts foreign sounds unlike Mandarin or Japanese.
The assumption here is that Mandarin was directly converted into onyomi. This assumption is wrong, as other Chinese languages, such as Hokkien, have more words closer to onyomi than Mandarin. However, for the sake of simplicity, Mandarin is assumed.
As a tonal language, Mandarin sounds, called pinyin (拼音), depend on the tone. Each pinyin sound can be paired to one of the four tones. While Japanese has a similar system called pitch accent, it is not as consistent as the tone. From a conservative standpoint, this essay considers neither Mandarin tones nor Japanese pitch accent. With this in mind, let’s compare the sounds in Japanese and in Mandarin.
The Onyomi Sound Bottleneck#
Mandarin consists of 21 initials (like b, p, m, f, d, t, n, l, g, k, h…) and roughly 35 to 39 finals (like a, o, e, ai, ei, ao, ou, an ,en, ang, eng, ong…). Combining all initials to all possible finals result in roughly 800 distinct syllables. In practice, however, there are approximately 412 distinct syllables. This would be the number of sounds Mandarin has.
Japanese has the gojūon, meaning “50 sounds”. However, there the 50 slots are not completely filled, leaving 46 base sounds. Adding dakuten and handakuten add 25 more sounds, and yōon adds 33. There are approximately4 104 sounds in Japanese.
With a phonetic inventory roughly one-forth the size of Mandarin’s, Japanese was already poorly equipped to accommodate the influx of Chinese vocabulary. This bottleneck is further narrowed by the fact that onyomi do not utilize the full gojūon spectrum, but are instead restricted to specific phonetic subset. For example, sounds like nu, ru, re, ne, and no are practically not utilized in onyomi. This renders the inventory to consist of about 70 or 80 sounds.
I am set on a mission to measure the loss of information that occurred when Mandarin pinyin gets converted into Japanese onyomi. I would do this calculation based on information theory, measuring information in entropy and perplexity.
Calculation#
(jump to conclusion if calculation matters less to you)
Using the Unihan Database, I scrapped all onyomi and its pinyin counterparts. The entropy is roughly in the following entropy calculation:
An example of the calculation is of the following:
Example: Japanese onyomi ‘kou’#
Let’s say that the sound ‘kou’ has the following sound distribution in pinyin:
- Source 1: hong (e.g., 宏, 弘) — 5 Kanji
- Source 2: geng (e.g., 更, 耕) — 3 Kanji
- Source 3: huang (e.g., 黄, 皇) — 2 Kanji
- Total Kanji Count (N):
Step A: Calculate Probability ()#
The probability is the “weight” of each Mandarin source within the kou bucket.
Step B: Calculate the “Surprise” ()#
Logarithm base 2 tells us how many “bits” of information are needed to represent that probability.
- hong:
- geng:
- huang:
Step C: Sum and Negate#
The formula ends with .
- Sum
- Final Entropy
The entropy is interpreted as the loss of information when a Mandarin kango is ‘imported’ into Japanese. The below table shows the top result for information loss.
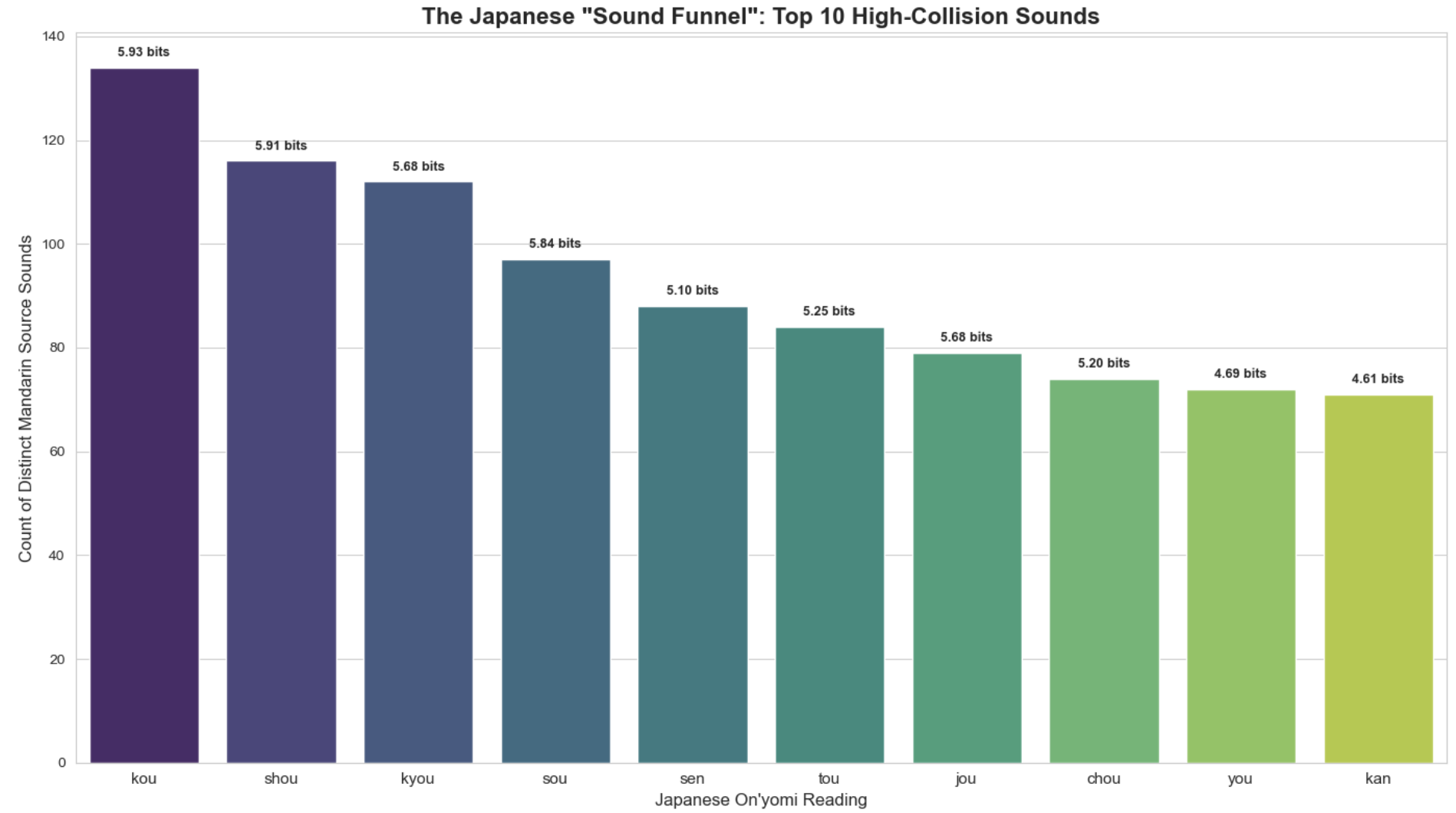
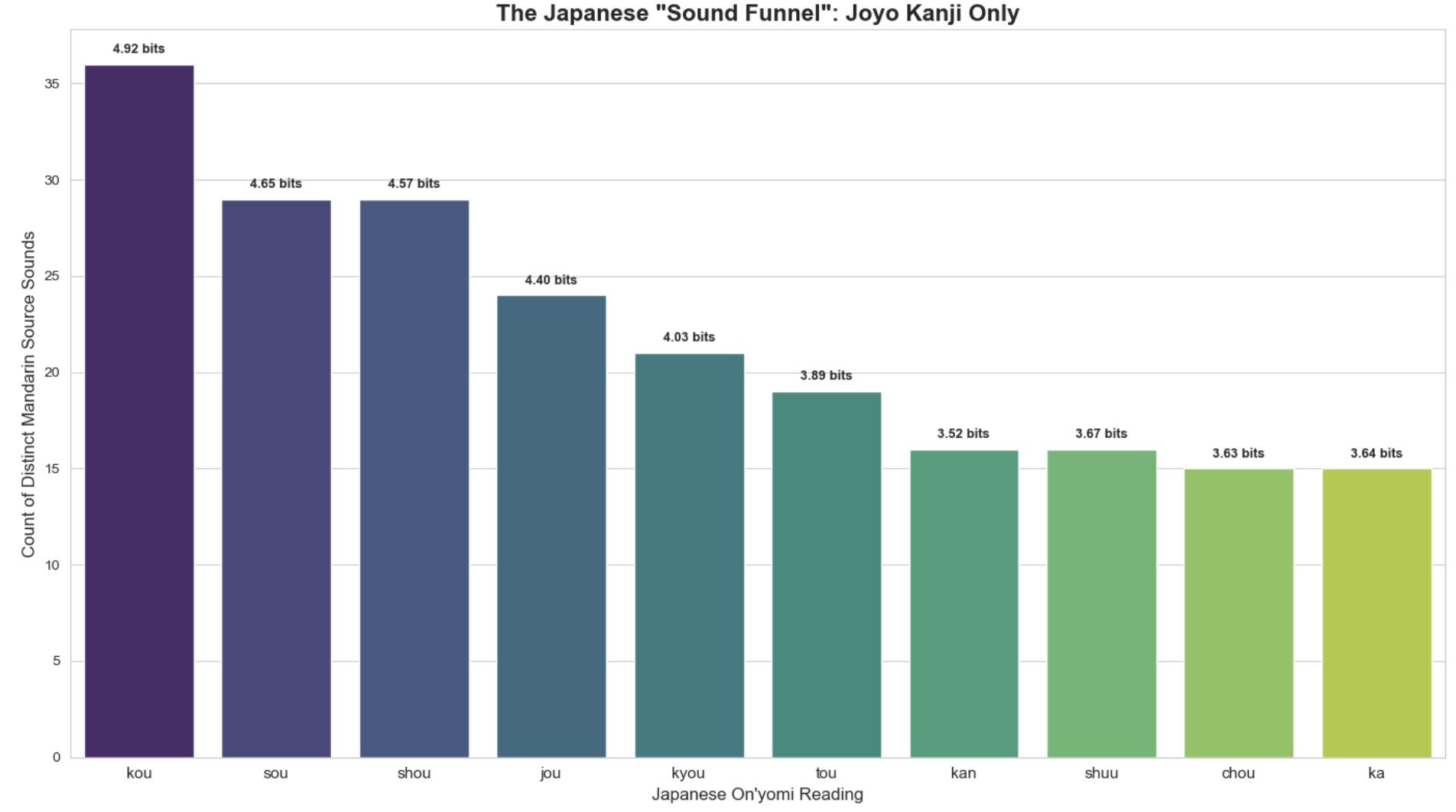
However, we can achieve a better representation by counting only jōyō kanji.
It can be further interpreted through perplexity with the following calculation:
is entropy. The perplexity of ‘kou’ in the jōyō kanji calculation is 30.27
Conclusion and Interpretation#
The data confirms that the transition from Chinese to Japanese on’yomi is a textbook case of high-loss information compression. By forcing approximately 412 Mandarin syllables into a restricted Japanese subset of roughly 70 to 80 sounds, the language created a massive phonological bottleneck.
The “Kou” Bottleneck#
As the entropy calculation shows, hearing a sound like kou creates a “Perplexity” of 30.27. In practical terms, this means that for a listener, hearing the syllable kou in isolation is mathematically equivalent to rolling a 30-sided die to guess the original Mandarin root. While the visual Kanji provides a “checksum” that perfectly identifies the word, the audio signal alone is often too noisy to be decoded without significant context.
Japanese has Kunyomi#
This high entropy explains why Japanese speakers naturally shift their strategy depending on the medium. While kango (Sino-Japanese words) provides a dense, efficient way to represent abstract concepts in writing, its 4.92-bit uncertainty makes it risky for spontaneous speech.
This explains the dramatic shift in vocabulary distribution: while kango dominates 60% of written text, it drops to only 18% in spoken Japanese. To maintain clarity, speakers prefer native wago or kun’yomi counterparts because they are typically longer and phonetically unique. A broadcaster, for example, might avoid the ambiguity of shiritsu (which can mean both “Private” 私立 and “Municipal” 市立) by using the kun’yomi-based phrases watakushi-ritsu or ichi-ritsu to ensure the information is “unzipped” correctly by the listener.
A Shared Regional Heritage#
Japanese is not alone in this struggle. Research shows that this “Sino-word” payload is a defining characteristic of the entire “Kanji Culture Sphere”. The proportion of Chinese-derived vocabulary is consistently high across the region1:
- Japanese: 43–54% of the vocabulary.
- Korean: 47–56% of the vocabulary.
- Vietnamese: Approximately 70% of the vocabulary.
In all three languages, these words are used stably at rates of 40% or higher across dictionaries, newspapers, and magazines. However, because the phonetic “compression” was so severe, the writing system—the Kanji themselves—remains the essential anchor for the language. I have yet to research Korean and Vietnamese abandonment of the Chinese characters, so I can only vouch for Japanese for the time being.
Final Thoughts#
Is the Kanji system “inefficient”? From a purely phonetic standpoint, yes. It requires years of study to master the 2,136 jōyō kanji. However, from an information theory perspective, Kanji is the essential error-correction code for the Japanese language. Without these visual IDs, the massive “lossy compression” of onyomi would render formal communication nearly impossible. We don’t use Kanji because it’s easy; we use it because, in a language with so much phonological collision, we need a visual way to see the difference between 30 different versions of “Kou.”
Footnotes#
-
国立国語研究所『テレビ放送の語彙調査I』(平成7年,秀英出版)Kokuritsu Kokugo Kenkyuujo, “Terebi Hoosoo no Goi Choosa 1” (1995, Shuuei Publishing) ↩
-
I haven’t found the original literature, but a quick search gives this result from researcher Chris Barker (via WayBackMachine) and from some Reddit user. ↩
-
The word “approximately” is chosen here because in practice, there are more subtle differences when pronouncing each of the kana. ↩